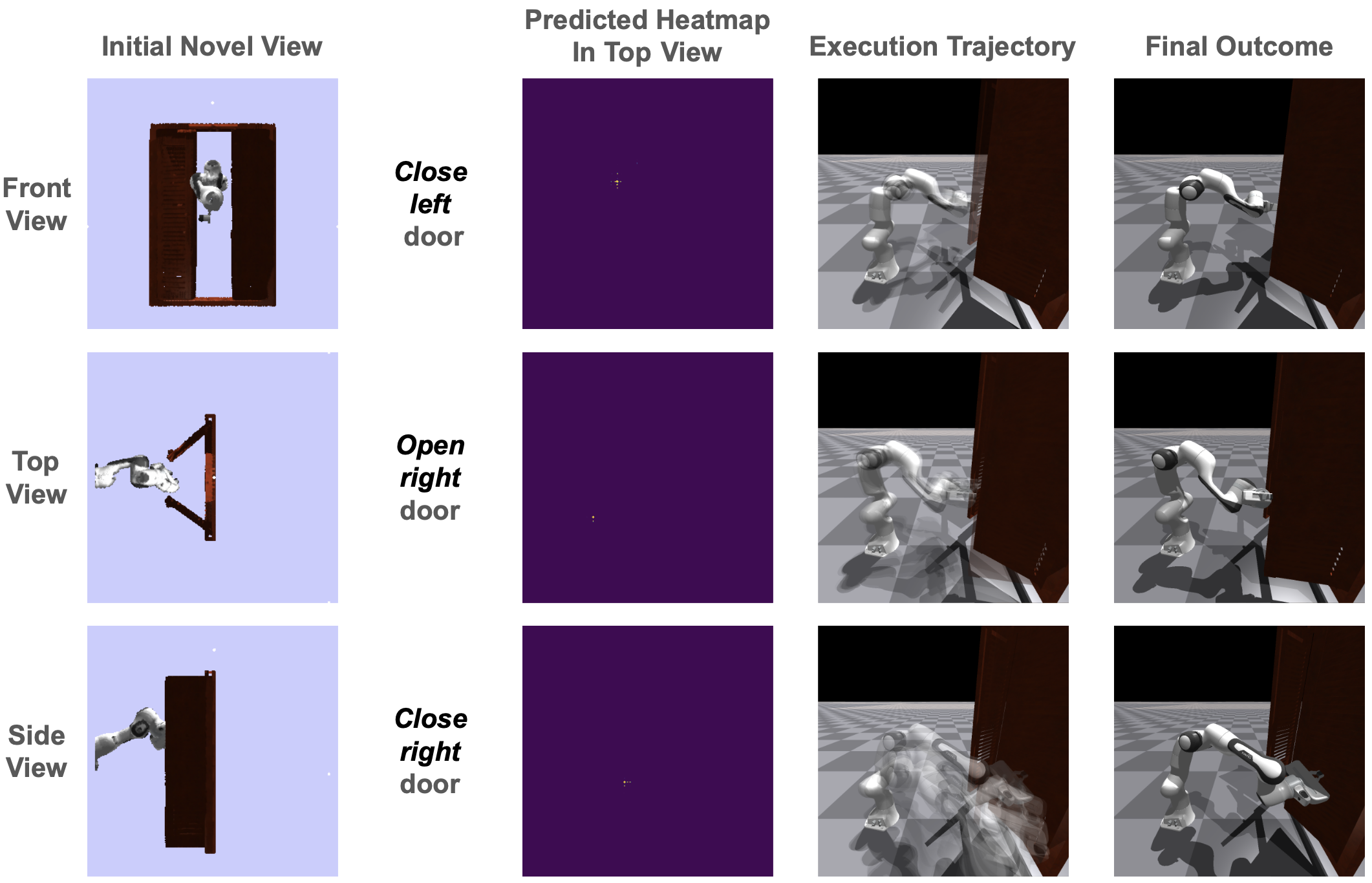
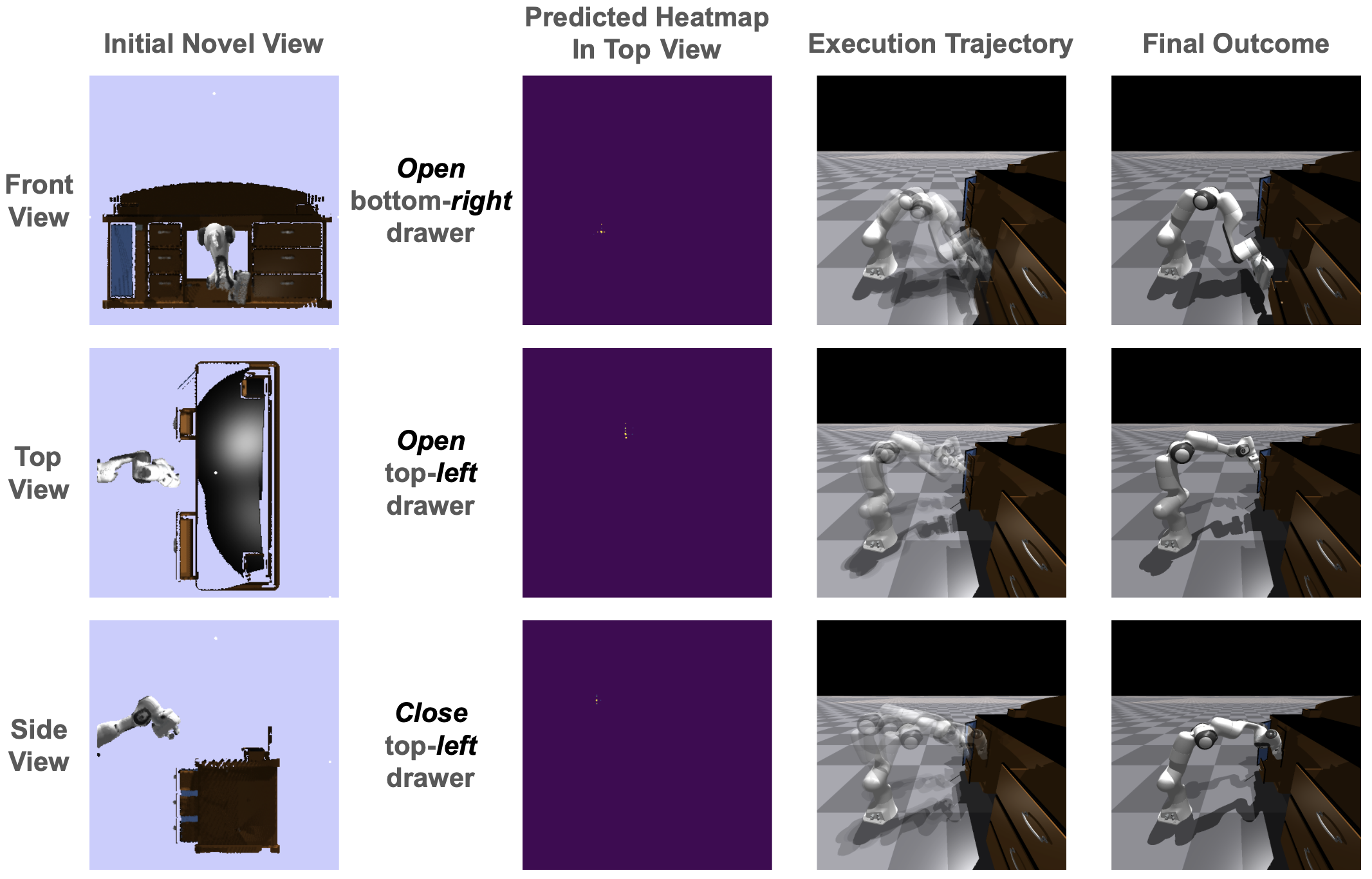
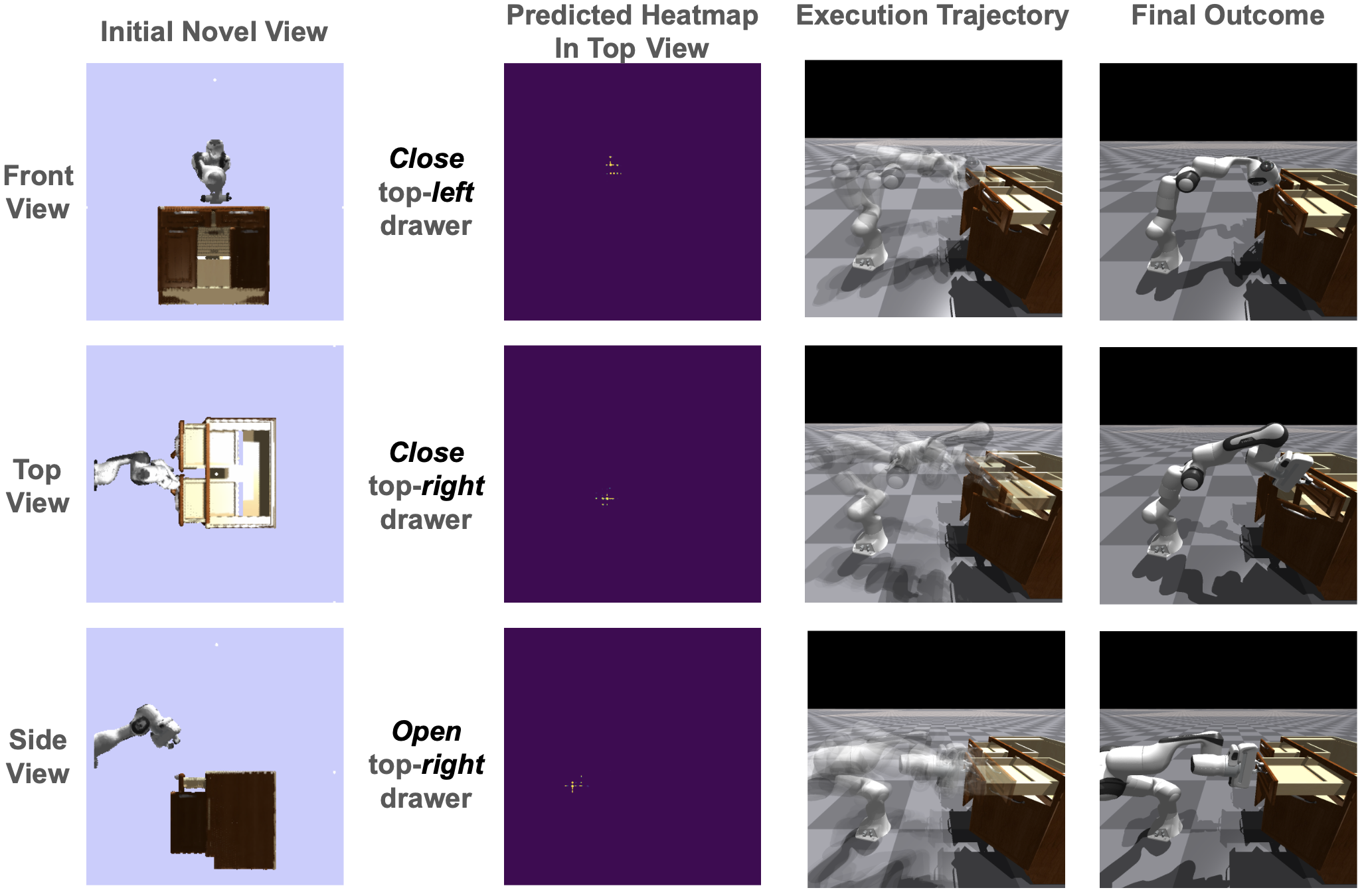
Imagine a robot that intuitively knows whether to open or close a drawer, selecting the appropriate action without any prior instruction or explicit programming. This level of autonomy has long been a challenge in robotics. However, recent advancements in AI and robotics by Liquan Wang and his team are turning this vision into reality with their innovative ActAIM2 model.
What's New in Robotic Learning?
In traditional robotics, teaching machines to recognize and act on different manipulation modes has been a significant hurdle. Most models struggle without direct supervision or predefined expert labels, limiting their ability to adapt to new tasks or environments. Enter ActAIM2—a breakthrough that equips robots with the ability to understand and execute complex tasks by learning interaction modes from scratch, without external labels or privileged simulator data.
Introducing ActAIM2: A New Way to Learn
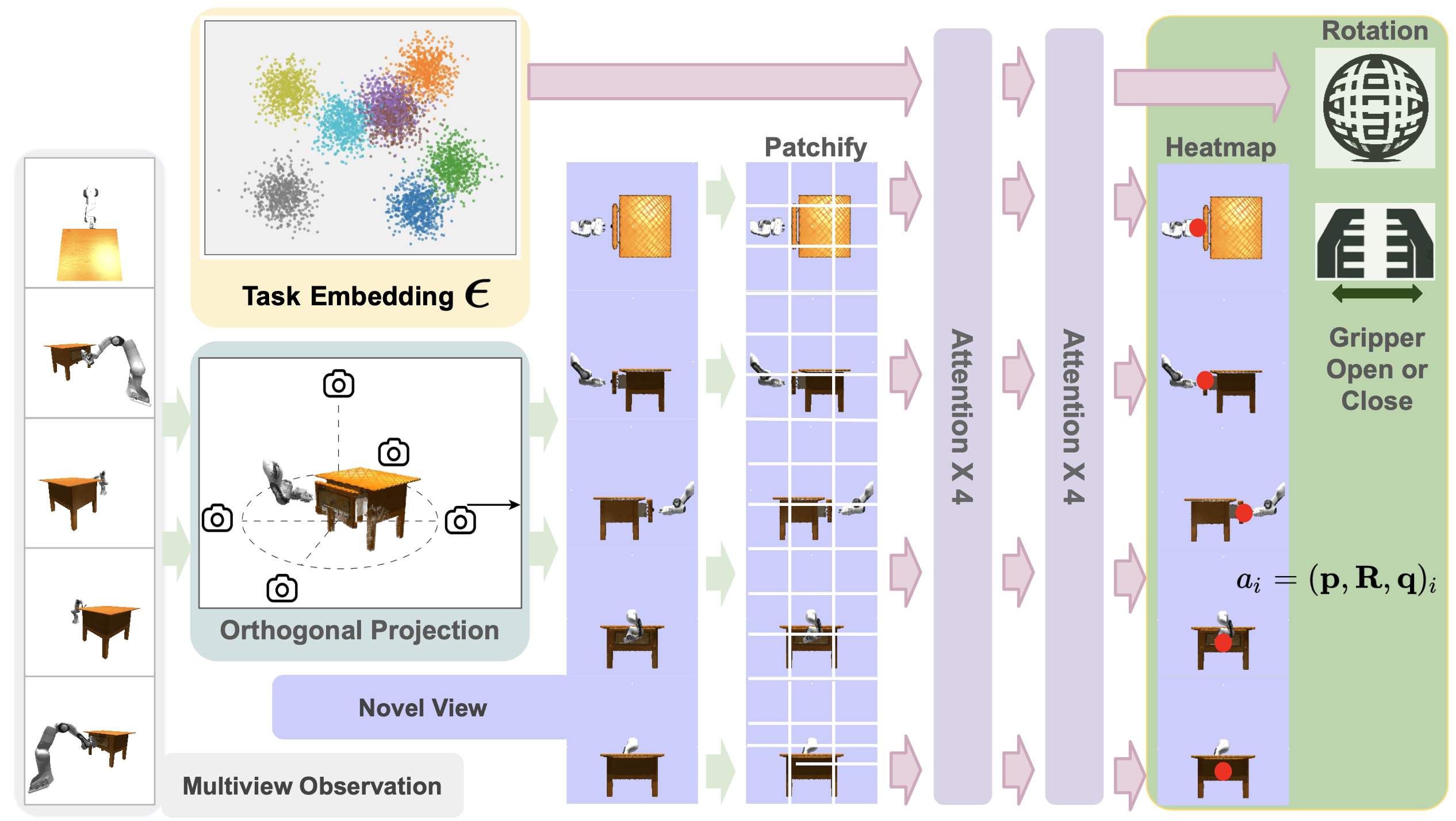
ActAIM2 distinguishes itself with a dual-component structure:
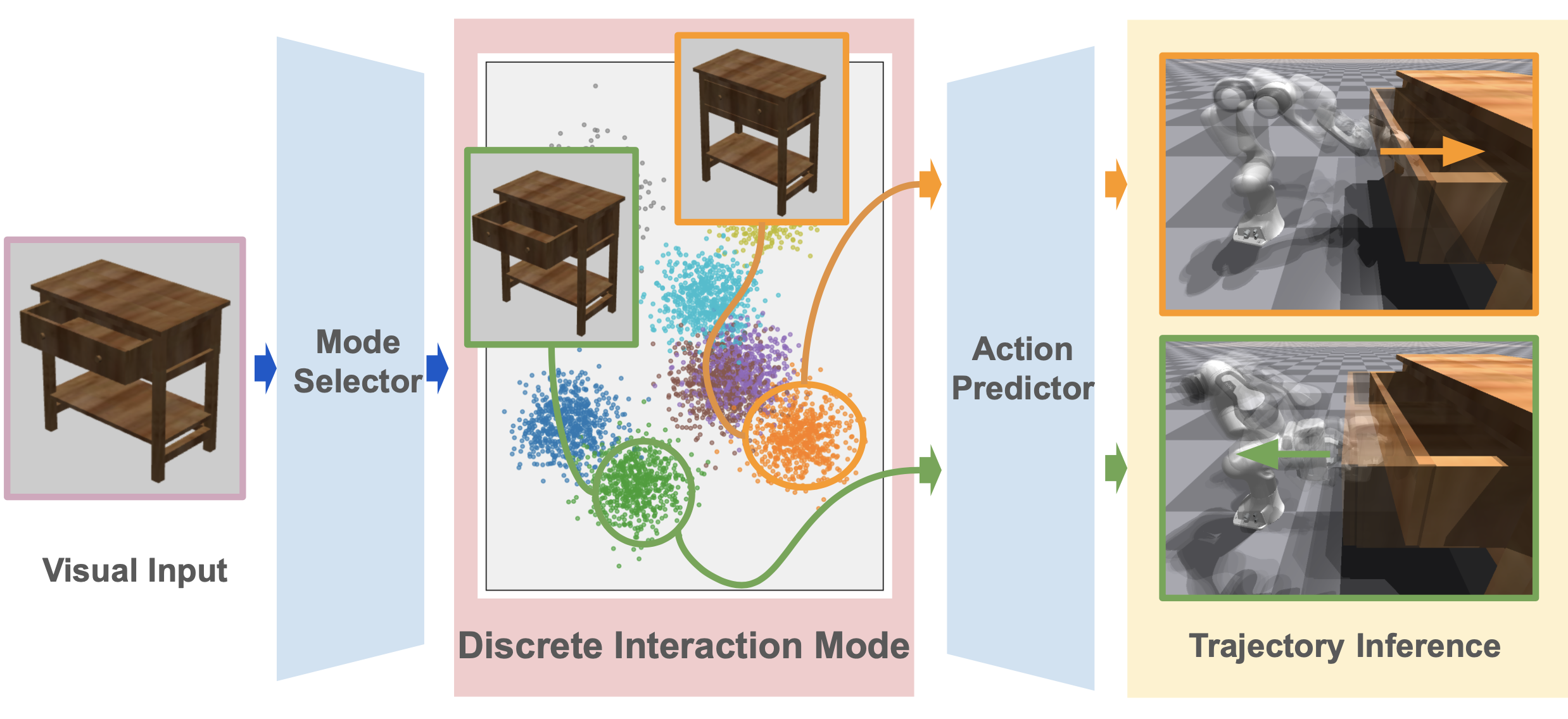
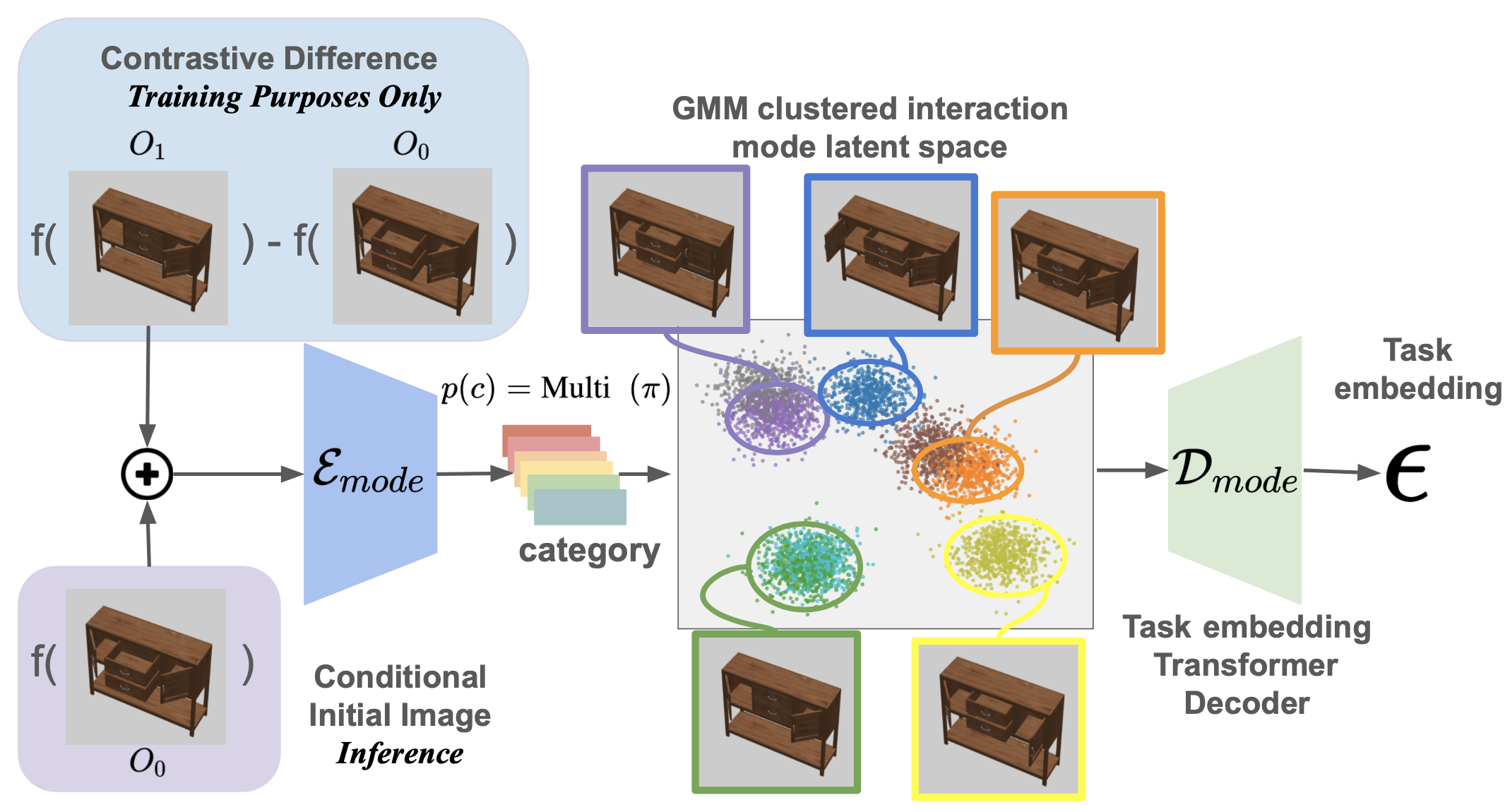
- Interaction Mode Selector: A smart module that captures and clusters different interaction types into discrete representations.
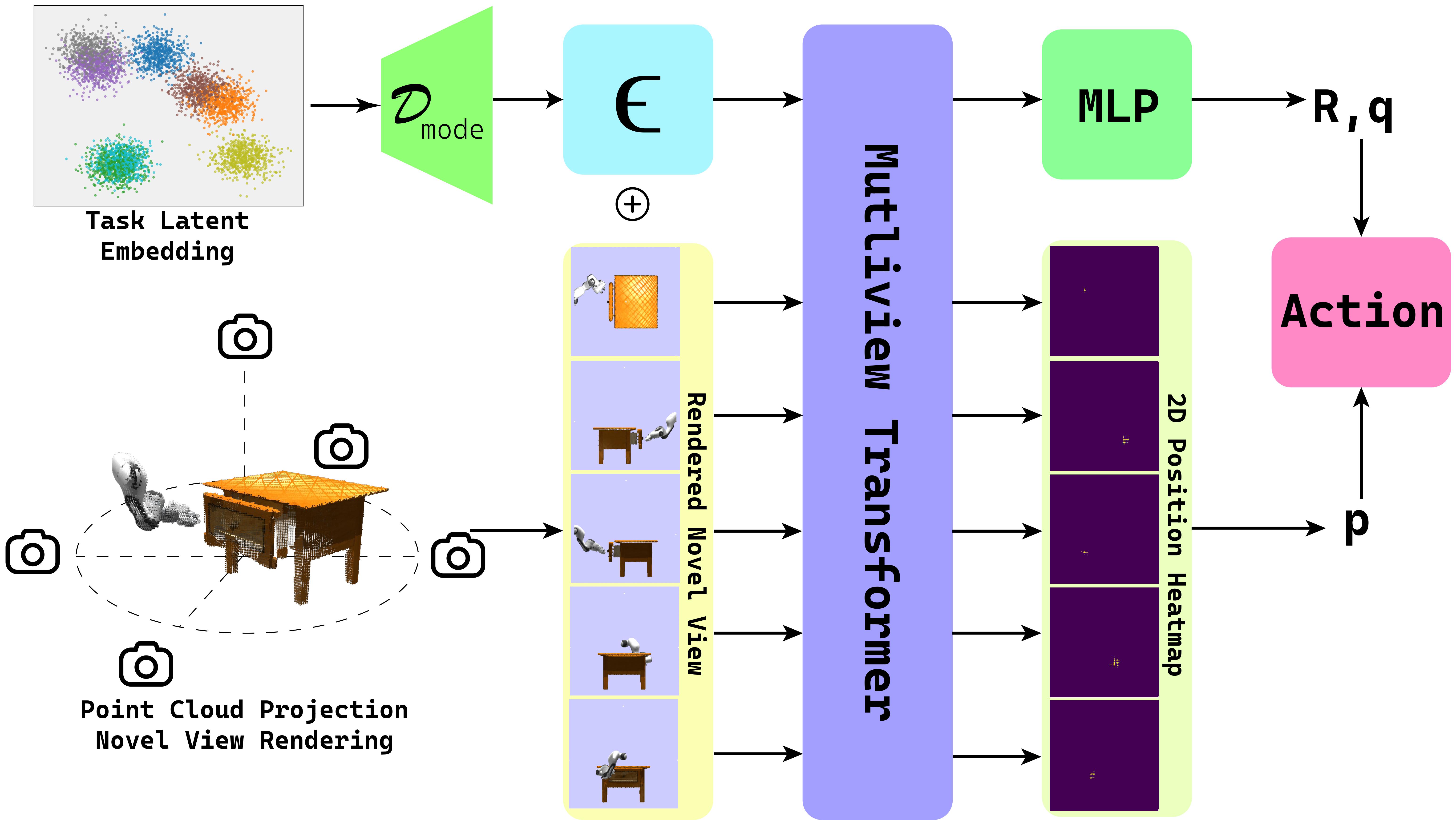
- Low-Level Action Predictor: A companion module that interprets these modes and generates precise actions for the robot to execute.
How Does ActAIM2 Work?
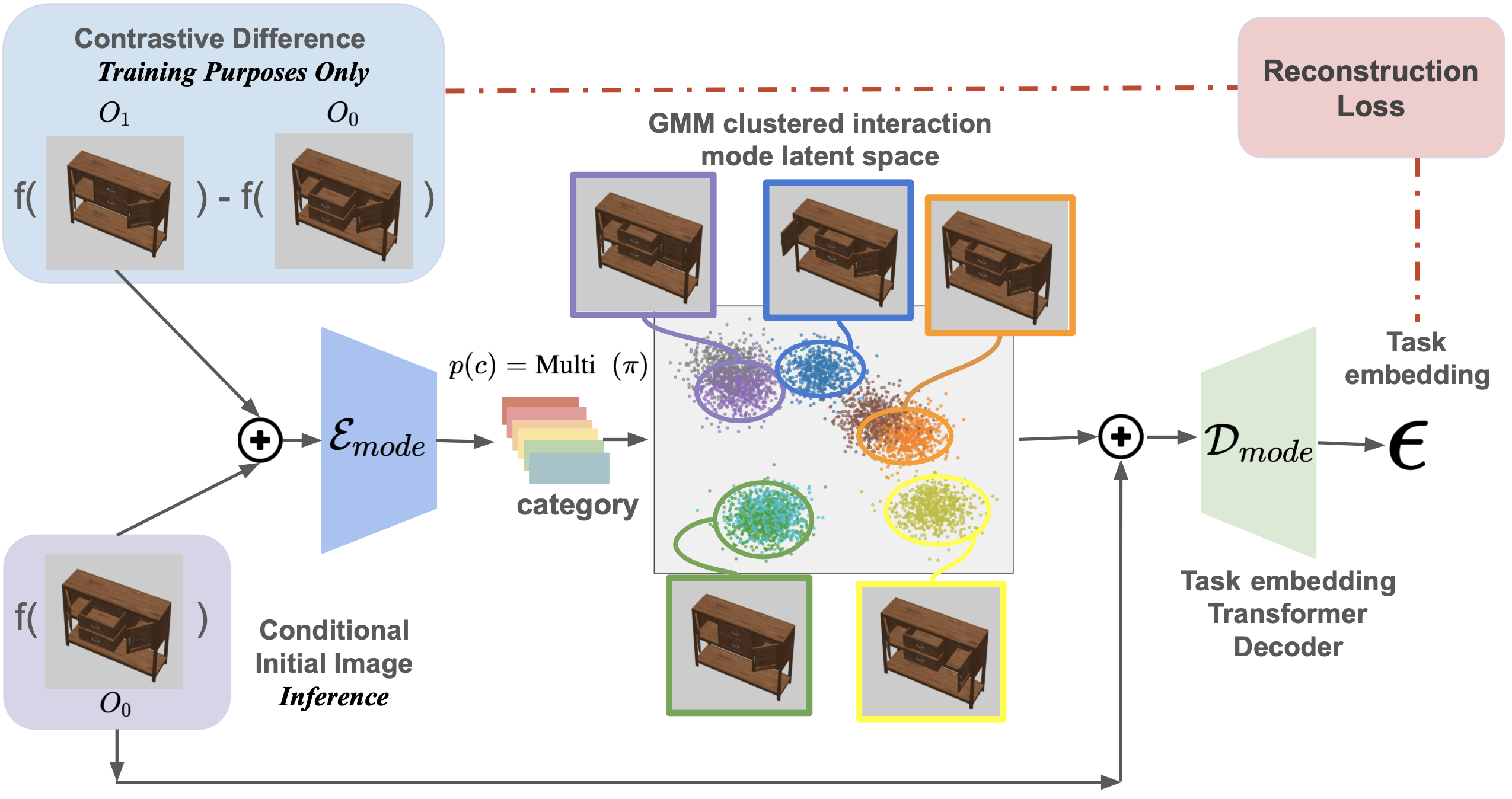
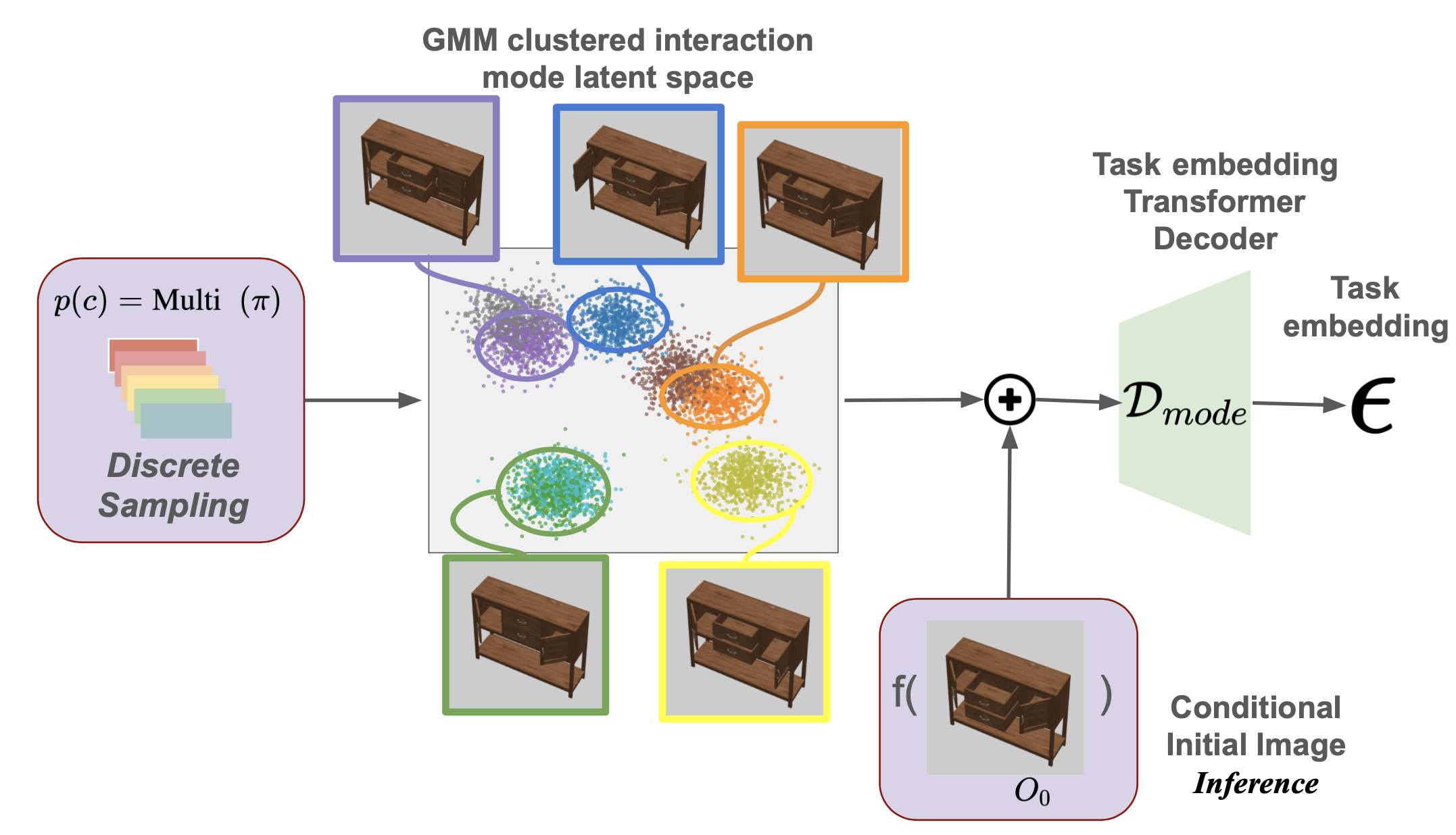
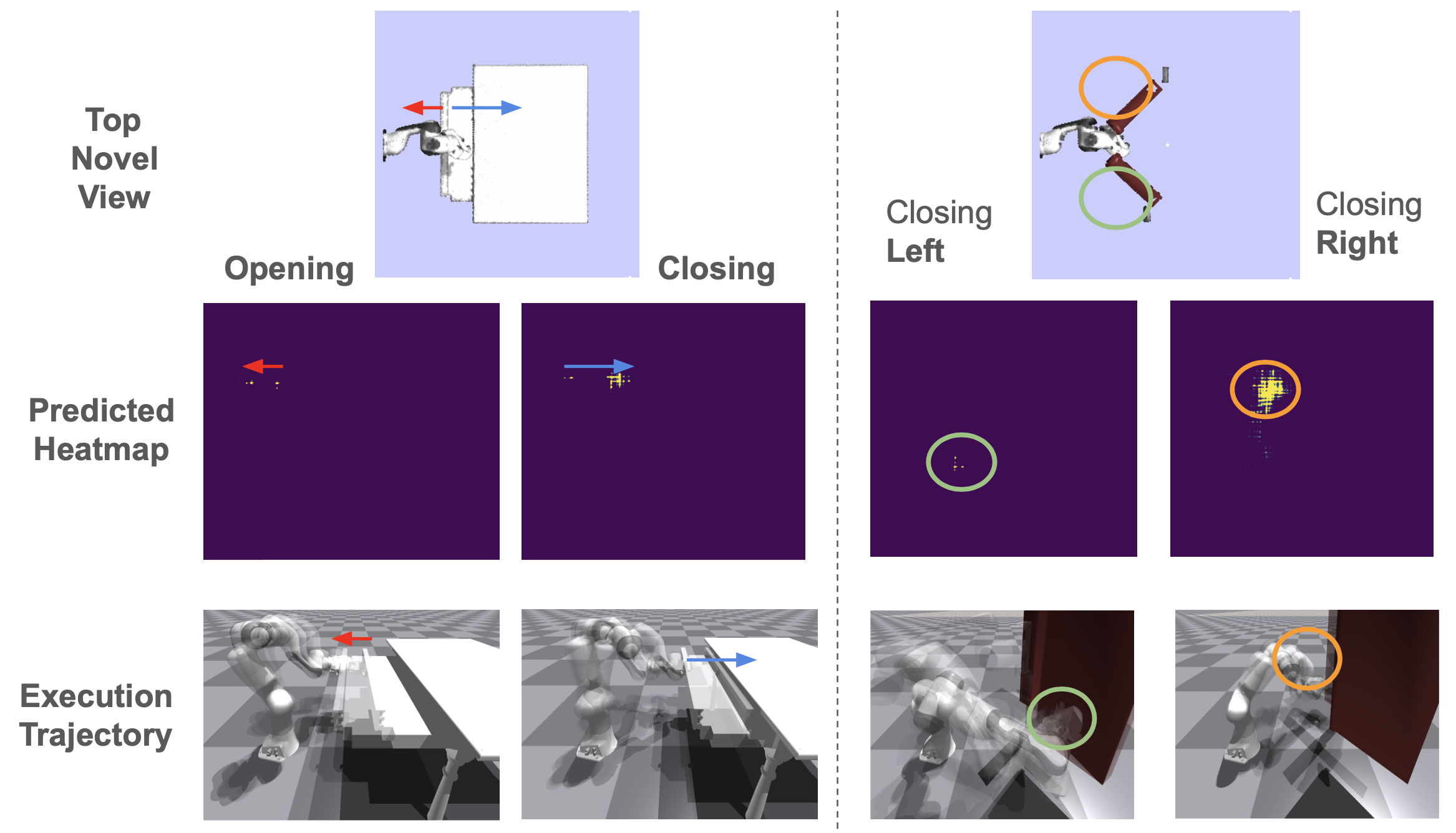
Think of ActAIM2 as a self-taught explorer. It observes simulated activities and picks up on the nuances of each task, using self-supervised learning to create clusters of interaction types. For example, the model can group actions related to opening or closing an object and then learn the specific movements required for each.
Key techniques that power ActAIM2 include:
- Generative Modeling: The mode selector uses generative processes to identify differences between initial and final states.
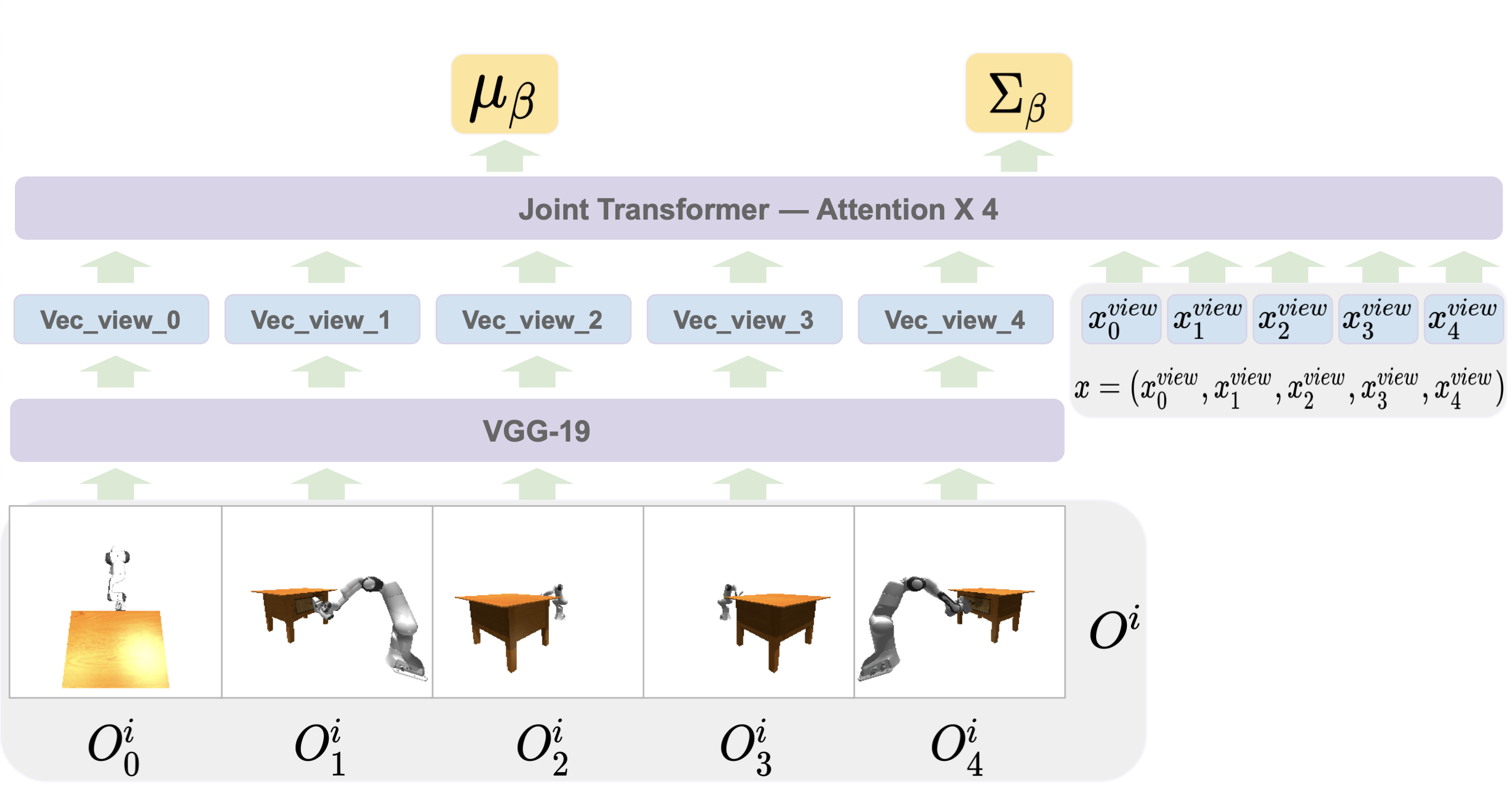
- Multiview Fusion: To build a robust understanding, the model integrates observations from multiple angles into a comprehensive visual input.
Why Is This Important?
This method marks a significant shift in how robots learn to interact with their environments:
- No Human Labels Needed: ActAIM2’s unsupervised learning approach means it doesn't rely on manually labeled data, making it highly adaptable and scalable.
- Improved Manipulability: By breaking down tasks into discrete interaction modes, robots can handle new tasks more efficiently.
- Enhanced Generalization: The model’s design enables it to apply what it learns to different scenarios, boosting performance across various tasks.
Real-World Implications
The potential impact of ActAIM2 spans multiple industries:
- Manufacturing: Robots that can autonomously switch between complex tasks like assembling or disassembling products.
- Healthcare: Assistive robots capable of safely operating in dynamic environments by understanding nuanced human requests.
- Service and Hospitality: Robots that can anticipate and perform tasks such as serving food or tidying spaces without specific training for each action.
Final Thoughts
The development of ActAIM2 represents a significant leap forward in autonomous learning for robots, unlocking the ability for machines to learn, adapt, and perform with minimal human oversight. It’s not just about creating more capable robots; it’s about making them smarter, more efficient, and better integrated into human-centered tasks. This innovation opens the door to a future where machines are not just tools but active, intelligent collaborators in our daily lives.